Successful validation (example based on large data sets)
The expert system is based on a variety of reliable models. Extremely large structure-activity relationships with up to hundreds of thousands molecules allow the estimation of useful drug-like chemical space. Structure-property relationships which are derived from PharmaInformatic´s in-house ADME/Tox-database predict ADMET properties and identify potential risks in order to reduce clinical failures. All models which are used in MolScore-Drugs have been tested with independent data sets.
Below is an example of the prediction result from one of these models. We have calculated the prediction ability with independent ("new") compounds. The first test data set contained 10.000 molecules such as proven and marketed drugs or compounds with known biological activity. The second test data set contained 20.000 non-drugs.
MolScore-Drugs
0 0,5 1
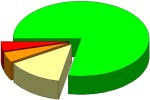
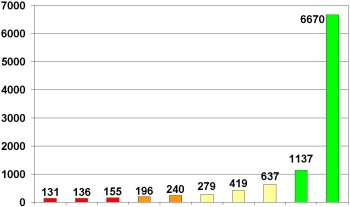
Prediction results on independent test data (10.000 compounds with known biological activity)
Number of molecules per row
79%
4%
13%
4%
MolScore-Drugs
0 0,5 1
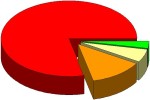
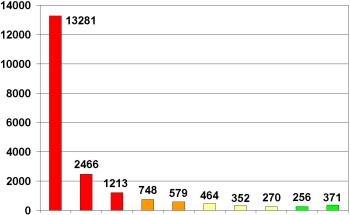
Prediction results on independent test data (20.000 non-drugs)
Number of molecules per row
79%
5%
13%
3%
27.428 compounds from 30.000 (91,4%) have been correctly predicted (decision threshold of drugs to non-drugs is set to 0,5). This gave an overall marginal error of only 8,6% in this particular model.
The obtained prediction quality was very high; about nine from ten predictions have been correct. Through the combination of different models, the prediction ability can exceed 95%.
Can blockbusters be detected by MolScore-Drugs? see detecting blockbusters.
MolScore-Drugs
can detect drugs
MolScore-Drugs
can detect non-drugs


|
|
|
© Copyright 2004-2021 PharmaInformatic Boomgaarden. All rights reserved. Site map Contact Terms of Use Imprint |

|
|